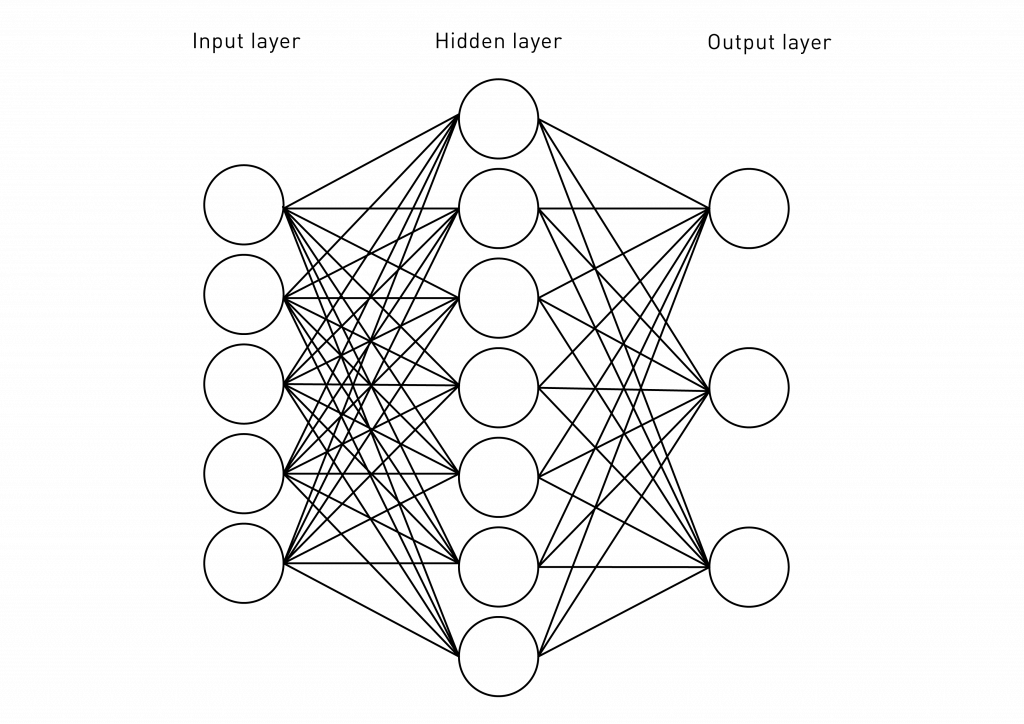
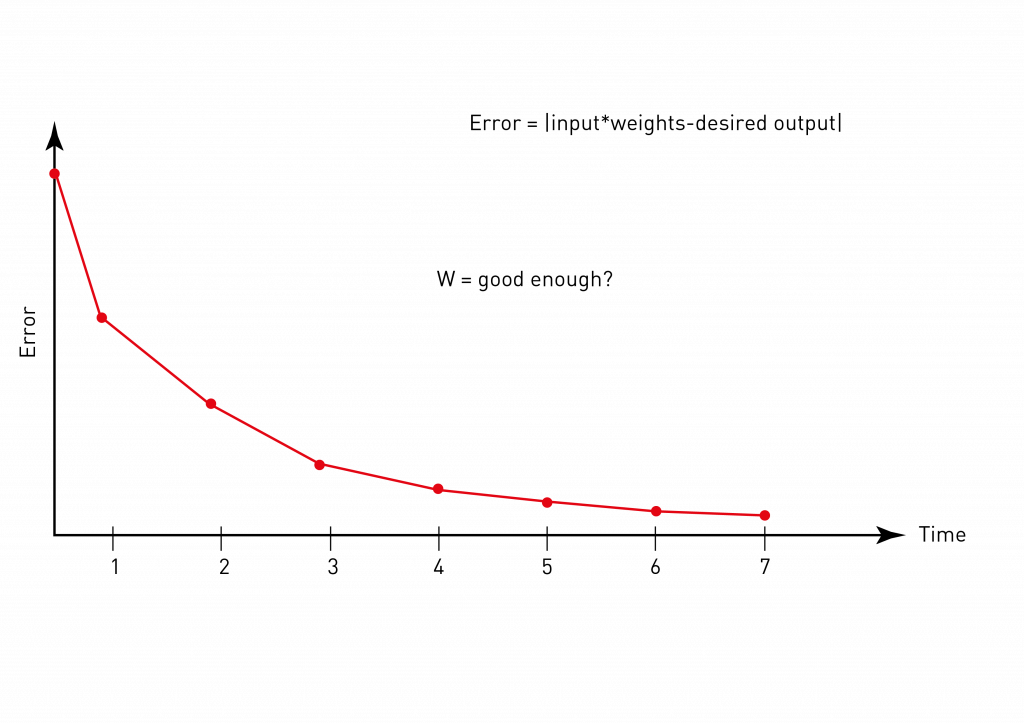
A neural network is a simple computational model, which consists of a vector of inputs, several computational units and outputs (Fig.1). Originally, such an approach to a model design was inspired by small parts of the human brain, neurons. In artificial neural networks, computational elements are also called neurons. They are organized in layers, typically called input layer, hidden layer and output layer, respectively. This type of neural network is called perceptron.Figure 1. Simple perceptron: computational elements, called neurons, are organized in layers (input, hidden and output layers).The main feature of a neural network is its ability to learn from examples, which is called supervised machine learning (or simply supervised learning). It is common to train the network on a number of examples: the example of an input and corresponding output. In the task of object recognition, the input would be an image and the output would be a label for this image (e.g. ‘cat’). Training of a neural network is an iterative process, which is designed to minimize the prediction error of the system (Fig. 2). It consists of steps, called epochs, at each of which the learning algorithm tries to minimize an error (usually, it would be thousands of training epochs) by adjusting connections between neurons: parameters of the network, called weights. At the end of the training process, the performance of the network is usually good enough to perform a certain task with an adjusted set of parameters.Figure 2. Training the intelligence of a neural network is an iterative process. With this approach, we aim to «guess» the value of the weights of a neural network with a machine learning algorithm at each step, in order to minimize an error. Error is calculated as a difference between the value, predicted by the network and the real image label.
What are deep neural networks
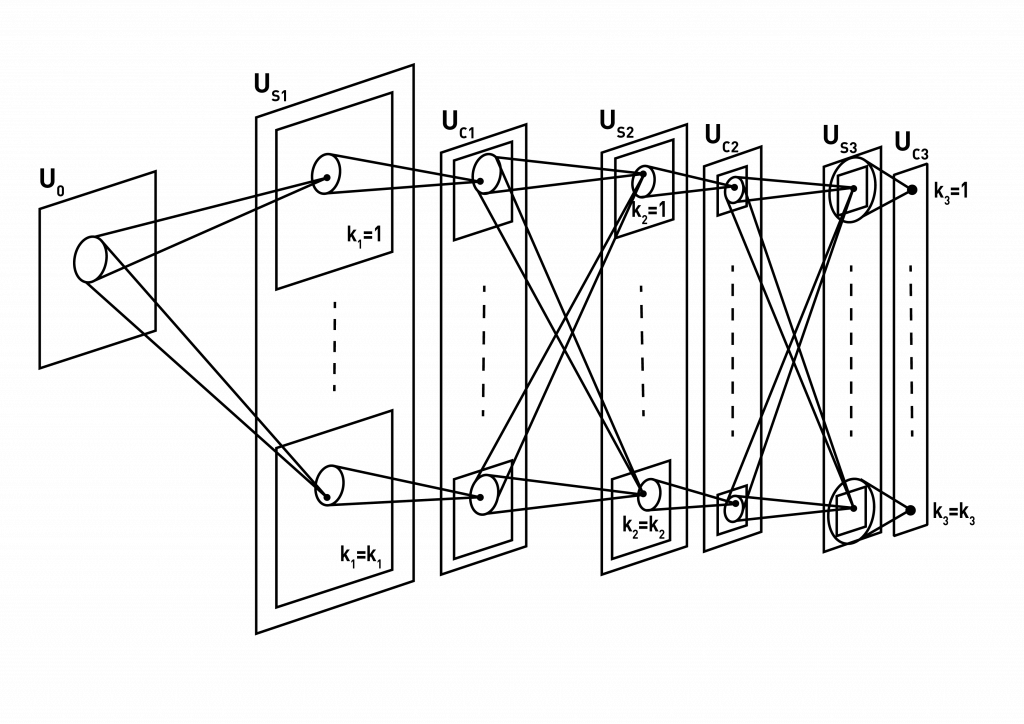
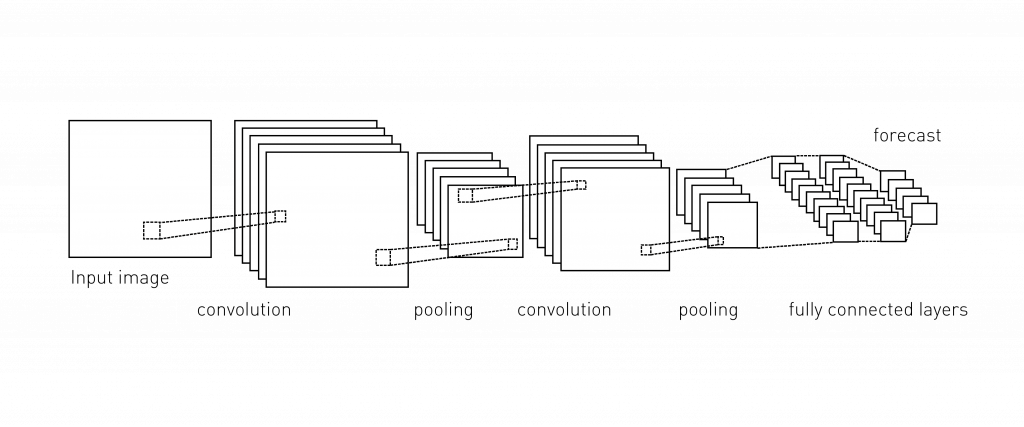
Deep neural network is an intelligent neural network with multiple hidden layers (Fig.3). This picture depicts a deep neural network and is intended to give a reader a general understanding of what a neural network is. However, the real architecture of deep neural networks is much more complicated.Figure 3. Neural network with multiple hidden layers.Convolutional nets are inspired by the visual system’s structure. The first computational model based on the concept of hierarchical organization of primate visual stream was Fukushima’s Neocognitron [1] (Fig.4). Modern understanding of the physiology of the visual system is consistent with the processing style found in convolutional networks, at least for the quick recognition of objects.Figure 4. Schematic diagram illustrating the interconnections between layers in the Neocognitron model [1].Later, this concept was first implemented by LeCun in his convolutional neural networks for handwritten character recognition [2]. This convolutional neural network was organized in layers of two types: convolutional layers and subsampling layers. Each layer has a topographic structure, i.e., each neuron was associated with a fixed two-dimensional position that corresponds to a location in the input image, along with a receptive field (the region of the input image that influences the response of the neuron). At each location of each layer, there are a number of different neurons, each with its set of input weights, associated with neurons in a rectangular patch in the previous layer. The same set of weights, but a different input rectangular patch, are associated with neurons at different locations.The overall architecture of a deep neural network for image recognition is depicted in figure 5. The Input image is represented as a number of pixels, or small image patches (e.g. 5-by-5 pixels).Figure 5. The schematic diagram of a convolutional neural network. The input image is divided into small patches, which serve as input to a neural network. These patches are processes with a hierarchical layers of filters, with increasing size of receptive fields in each step of processing. The detection of a certain type of feature occurs then at each layer. The resulting features are processed with a simple classifier (e.g. multi-layer perceptron or support vector machine) in order to produce a forecast.Usually, deep neural networks are depicted in a simplified manner: as a number of processing stages, sometimes referred to as ‘filters’. Each stage differs from another by a number of characteristics, such as receptive field properties, type of features detected and a type of computation performed at each stage [3].The applications of deep neural nets, including convolutional neural networks (CNNs), are not restricted to image and pattern detection and recognition applications. CNNs are widely used to recognize speech and audio inputs, mobile sensor input processing and biomedical imaging processing [4].
Neural Networks for facial features recognition
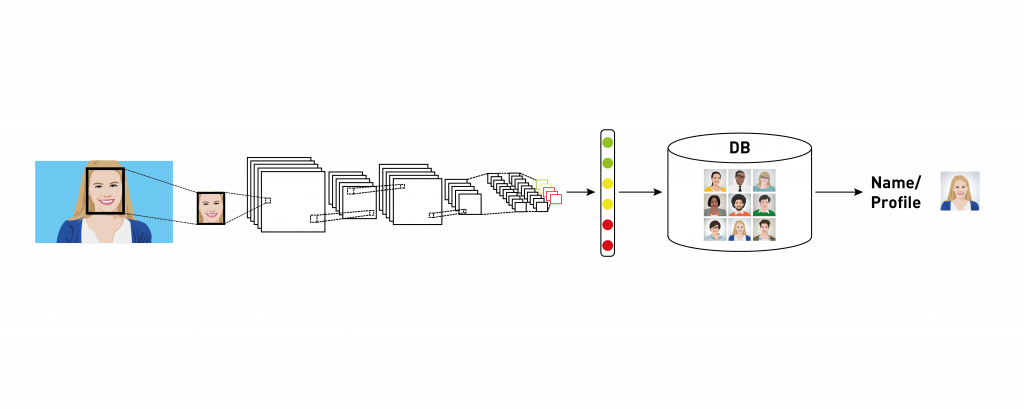
In order to become more intelligent and achieve good detection and recognition accuracy, the neural network is pre-trained on a large number of images such as the MegaFace database.Figure 6. The MegaFace dataset contains 1 million images representing more than 690,000 unique people. It is the first benchmark that tests facial recognition algorithms at a million scale. University of Washington.After the network is trained to recognize faces, the workflow of the trained network could be described as following. At first, the image is processed with a face detector: algorithms, which detect a rectangular patch of an image with a face. This patch is normalized in order to be easier processed with a network. After the normalization, the image of a face serves as an input to a deep neural network. The neural network builds a unique feature vector, which is then transferred to a database. The search engine compares it with all the feature vectors, stored in the database, and gives a result of a search as a number of names or profiles of users, with similar facial feature vectors with a number assigned to each of them. This number represents a degree of similarity of our feature vector with those found in a database.Figure 7. The process of face recognition
Assessing the accuracy of the algorithm performance
Accuracy
When we choose what artificial intelligence algorithm to apply to the object or face recognition problem, we need to have a means of comparison of the performance of different algorithms. This part will address choosing a tool for this.For each application, there is a set of metrics that can be used to assess the performance of the system. Each metric would produce a score of the system, which can be compared to the score of the competitor system.Generally, any intelligent neural network system can be measured with the accuracy: after parameter adjustment and learning, the performance of the resulting function should be measured on a test set that is separate from the training set. Typically, this parameter is a quantitative measure: a number (often a percentage) that shows how well the system can recognize unseen objects. One more typical measure is an error (equals 100% - accuracy percentage). However, for biometrics more precise measures exist.In biometrics, there are two types of applications: verification and identification. Verification is the process of affirming that certain identity is correct by comparing the image (or another feature vector, e.g. fingerprint data) of identity with one or more previously saved templates. A synonym for verification is authentication. Identification is a process of determining the identity of an individual. A biometric sample is collected and compared to all the templates in a database. Identification is close-set if the person is assumed to exist in the database. Therefore, recognition is a generic term that could imply either or both verification and identification.Often the term similarity score is used in biometric applications. A larger similarity score indicates that the two biometric samples being compared are more similar. For each task (identification and verification), different tools would be used to measure similarity.We’ll talk about these metrics in one of the next posts. Stay tuned! And don’t hesitate to leave your comments beneath.
Fukushima, «Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position,» Biological Cybernetics, 1980.
LeCun, B. Boser, J.S. Denker, D. Henderson, R.E. Howard, W. Hubbard and L.D. Jackel. «Backpropagation Applied to Handwritten Zip Code Recognition», Neural Computation, vol. 1, pp., 541−551,1989.
Ian Goodfellow, Yoshua Bengio, Aaron Courville (2016) Deep Learning. MIT press.
Jiaxuan You, Xiaocheng Li, Melvin Low, David Lobell, Stefano Ermon
Deep Gaussian Process for Crop Yield Prediction Based on Remote Sensing Data.