

Dear friends! Talking about a variety of Artificial Neural Networks areas of application is impossible and incomplete without the story of the very neural network, the history of its research and the main types of artificial neural systems.
Introduction
One of the most significant innovations in the research world in the past decade is the introduction of neuroscience and computer vision-based applications in image and scene understanding. Since the middle of the previous century, the problem of object recognition was considered the most complicated task in computer vision.
Object recognition is the most basic and fundamental property of our visual system. It is the basis of other cognitive tasks, like motor actions and social interactions. Therefore, the theoretical understanding and modelling of object recognition is one of the central problems in computational neuroscience.
For the majority of people, visual perception is considered to be the most important of five senses, which they use in everyday life. Almost two thirds of the information we receive from our senses is visual information. There is a wide range of the tasks we perform during visual perceptual processing: finding the objects in the image that attract our attention, understanding what objects they do represent regardless of the position and size changes, overcoming the luminosity and colour changes, recognition of cluttered objects and many others. Humans perform these tasks without any effort. However, these tasks appear to be extremely difficult when we try to simulate them with an artificial system.
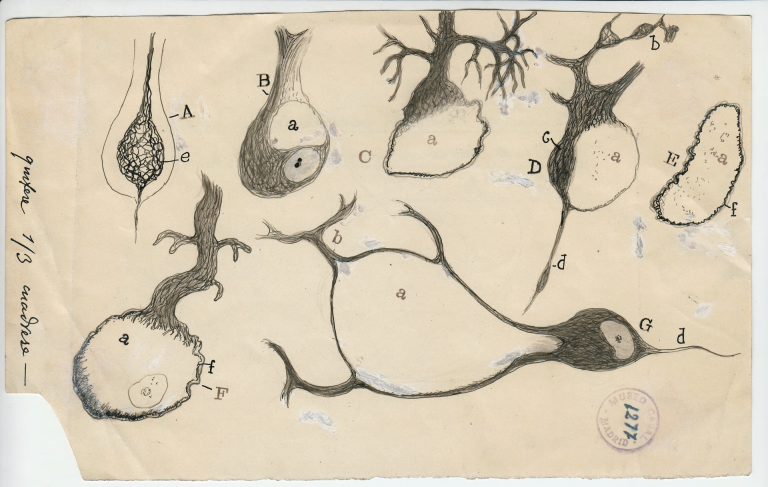
One of the pioneers in the research of neural cells was a Spanish neuroscientist and Nobel laureate Santiago Ramón y Cajal, who was the first to describe and draw top to bottom (as long as we speak about the 19th century) the main types of a man’s brain nerve cells. His wonderful drawings you can see here. Of cause now we know some of his conclusions were wrong but the main principles of brain functioning he described correctly.
Several generations of scientists after Ramón y Cajal studied the basics of this most complex human organ, but even today we do not fully understand a lot of brain functions. Approximately starting from the 1950s, scientists tried to model the work of the brain with the help of analog[1] and then digital neural networks. The concept of an artificial neural network was introduced by Warren McCulloch and Walter Pitts in 1943[2]. The principles of neural networks learning were originally taken from the fundamentals of brain work and the rules of building synapses — the structures that permits a neuron (or nerve cell) to pass an electrical or chemical signal to another neuron[3].
As a result there was proposed a hierarchical view of human visual system, based on the layers of complex and simple cells in visual cortex. In the second half of the previous century, this concept of hierarchies in the visual processing stream was first utilized by computer vision scientists to build the first theoretical hierarchical model for object recognition. The biologically plausible models, neural networks were utilized in computer vision for the last few decades already. However, until recently the computational complexity of this type of architecture would not allow the researchers to build and train the real complex model, based on this theoretical structure. Only about 10 years ago, the first models of this kind started to appear. Due to the complex multi-layer structure these architectures were called ‘deep'.
The accuracy of modern computer vision systems is higher than that of the human[4]. They are able to perform multiple tasks: low-level visual recognition tasks such as boundary detection, mid-level tasks (saliency detection, semantic segmentation) and high-level tasks as object identification.
In this paper, we will briefly describe the technology, which underlies all these tasks and describe the basic principle of the application of this technology to the problem of face recognition.
The challenge of face recognition
In comparison to general object recognition tasks, face recognition is more challenging, since it requires more precise tools for face detection, recognition and identification. There are many challenges: presence of occlusions (hair, glasses, masks, beard); colour, lightning and illumination changes; head rotations, age etc.
In addition to these obvious problems, there are also specific difficulties, connected with face recognition like:
- the ability to catch the subtle differences between faces of similar people
- the ability to describe classes of objects that are not in the training sample
Due to all these reasons, a problem of face recognition for biometrics is typically considered to be a difficult one.
Technology description
There are many computer vision systems for image recognition. Many approaches have been used before, such as the scale-invariant feature transform (SIFT), an algorithm in computer vision to detect and describe local features in images, or the histogram of oriented gradients (HOG), a feature descriptor used in computer vision and image processing for the purpose of object detection. In a typical object recognition task, one of these algorithms is usually combined with a simple classifier, such as support vector machine (SVM) to perform an object recognition task. However, the neural-network approach prevails in the market, since it largely outperforms conventional approaches since 2012.
The performance of different image recognition approaches is compared in on the annual Imagenet Large Scale Visual Recognition Challenge (ILSVCR) since 2010. ILSVCR is a competition where research teams submit programs that classify and detect objects and scenes. In 2012, a deep convolutional neural net achieved the best accuracy in the history by surpassing the competitors at 16%. Since then, convolutional nets were winning all the challenges until now. By 2015, researchers had reported that software exceeded human recognition abilities in some ILSVCR tasks. Therefore, neural network approaches, especially convolutional neural networks, are considered (if sufficient data are available) to be the best performing algorithms for image recognition (please look up here and here).
Similar challenge, but for face recognition on images, was introduced in 2015 (first MegaFace challenge). The data set for this challenge included one million photos capturing more than 690K different individuals. The neural network-based algorithms outperformed all the conventional methods and won both 2015 and 2016 challenges.
By the way, in 2015, it was the NtechLab algorithm that won the MegaFace challenge, beating the world’s leading digital labs, including Google, Beijing University, and several teams from around Russia.
What actually neural network is? what are the main types of artificial neural networks? How the machine learning process works? We’ll tell you more and deep about it in one of the following posts. Do not switch! And please feel free to post your comments or questions.
[1] Rosenblatt, Frank (1957), The Perceptron-a perceiving and recognizing automaton. Report 85−460−1, Cornell Aeronautical Laboratory.
[2] A logical calculus of the ideas immanent in nervous activity // Bulletin of Mathematical Biology. — New York: Springer New York, 1943. — Т. 5, № 4. — С. 115—133.
[3] Donald Olding Hebb. The Organization of Behavior: A Neuropsychological Theory. — Wiley, 1949. — 335 p
[4] Fukushima К., Miyake S., Takayuki I. Neocognitron: A neural network model for a mechanism of visual pattern recognition. IEEE Transaction on Systems, Man and Cybernetics SMC-13(5):826−34. — 1983.