

مرحبا بالجميع!
كما وعدناكم في المرة السابقة ، سنخبركم كيفية تقييم خوارزميات التعرف على الوجوه. تم تحضير المواد من قبل طاقم مختبر NtechLab.
في الآونة الأخيرة ، اجتذب إتجاه تطوير التعرف على الوجوه اهتمامًا متزايدًا من جانب القطاع التجاري والدولة. ومع ذلك ، فإن القياس الصحيح لدقة عمل هذه الأنظمة ليس بالمهمة السهلة ويحتوي على الكثير من الفروق الدقيقة. يتم الاتصال بنا باستمرار لطلبات اختبار تقنية التعرف الخاصة بنا والمشاريع التجريبية القائمة عليها، وقد لاحظنا أنه غالبًا ما تكون هناك أسئلة حول المصطلحات وطرق اختبار الخوارزميات فيما يتعلق بمشاكل ومهام العمل. نتيجة لذلك ، قد يتم اختيار أدوات غير مناسبة لحل المشكلة ، مما يؤدي إلى خسائر مالية أو خسارة أرباح. قررنا نشر هذا المنشور لمساعدة الأشخاص على التعرف على المصطلحات الفنية والبيانات الأولية المحيطة بتقنيات التعرف على الوجوه ولجعل المقارنات أسهل. أردنا إخباركم بالمفاهيم الأساسية في هذا المجال بلغة بسيطة ومفهومة ، لتوضيح كيفية عمل نظام التعرف على الوجوه القائم على الخوارزمية. نأمل أن يسمح ذلك للأشخاص ذوي العقلية التقنية والأشخاص من قطاع الأعمال بالتحدث بنفس اللغة ، وفهم سيناريوهات استخدام التعرف على الوجوه بشكل أفضل في العالم الحقيقي، واتخاذ قرارات مؤكدة البيانات.
مهام التعرف على الوجوه
غالبًا ما يُشار إلى التعرف على الوجوه على أنه مجموعة من المهام المختلفة ، على سبيل المثال ، اكتشاف وجه في صورة أو وجه في تدفق فيديو ، أو تحديد الجنس والعمر ، أو العثور على الشخص المناسب من بين صور متعددة للوجوه ، أو التحقق من أن نفس الشخص موجود في صورتين. في هذه المقالة ، سنركز على المهمتين الأخيرتين وسندعوهما ، على التوالي ، تحديد الهوية والتحقق. لحل هذه المهام ، يتم استخراج واصفات الوجوه الخاصة ، أو متجهات العلامات المميزة الضرورية للتعرف على الوجوه ، من الصور. في هذه الحالة ، يتم تقليل مشكلة تحديد الهوية إلى البحث عن أقرب متجه للعلامات المميزة ، بينما يمكن تنفيذ التحقق باستخدام جزء بسيط للمسافات بين المتجهات. من خلال الجمع بين هذين الإجراءين ، يمكن للمرء تحديد شخص من بين مجموعة من صور الوجه أو تحديد أنه ليس من بين هذه الصور. هذا الإجراء يسمى open-set identification (تحديد الهوية علي مجموعة مفتوحة)، انظر الشكل 1.
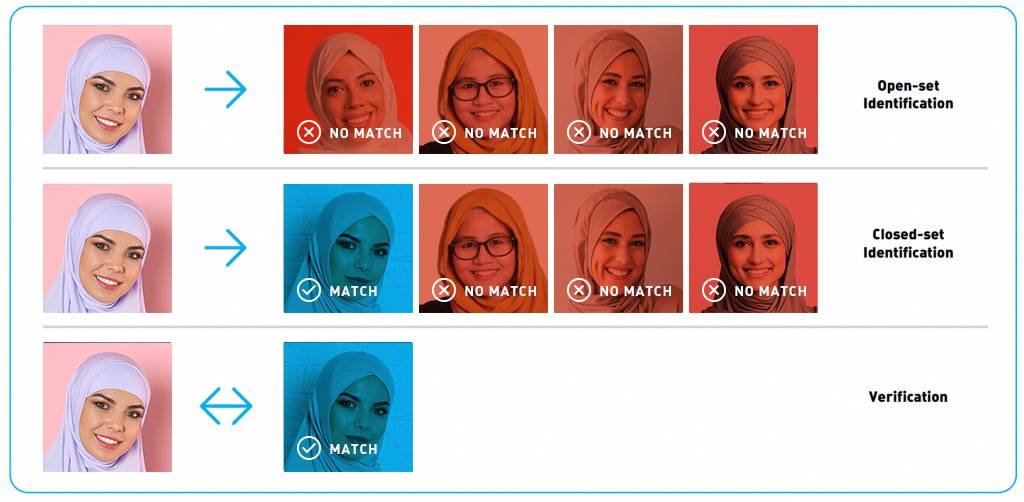
لتحديد تشابه الوجوه ، يمكنك استخدام المسافة في مساحة إتجاهات ملامح الوجه. غالبًا ما يتم اختيار المسافة الإقليدية أو مسافة جيب التمام ، ولكن هناك طرق أخرى أكثر تعقيدًا للتعرف. غالبًا ما يتم توفير وظيفة المسافة كجزء من منتج التعرف على الوجوه. يؤدي تحديد الهوية والتحقق إلى نتائج مختلفة ، وبالتالي ، يتم استخدام مقاييس مختلفة لتقييم جودتها. سنلقي نظرة فاحصة على مقاييس الجودة في الأقسام التالية. بالإضافة إلى اختيار مقياس مناسب ، هناك حاجة إلى مجموعة مصنفة من الصور (مجموعة البيانات) لتقييم دقة الخوارزمية.
تقييم الدقة
مجموعات البيانات
تم بناء جميع البرامج الحديثة للقياسات الحيوية للوجه تقريبًا على التعلم الآلي. يتم تدريب خوارزميات التعرف على الوجوه على مجموعات البيانات الكبيرة مع الصور ذات العلامات. كل من جودة وطبيعة مجموعات البيانات هذه لها تأثير كبير على الدقة. كلما كانت البيانات الأولية أفضل ، كلما تعاملت الخوارزمية بشكل أفضل مع المهمة المطروحة.
تتمثل الطريقة الطبيعية لاختبار مدى دقة عمل نظام التعرف على الوجوه في قياس دقة التعرف على اختبار منفصل لمجموعة بيانات. من المهم جدًا اختيار مجموعة البيانات المناسبة. من الناحية المثالية ، يجب أن تكتسب المنظمة مجموعة البيانات الخاصة بها ، والتي تكون مشابهة قدر الإمكان للصور التي سيعمل بها النظام أثناء التشغيل. انتبه إلى الكاميرا وظروف التصوير والعمر والجنس وقومية الأشخاص الذين سيتم تضمينهم في مجموعة البيانات التي سيتم إختبارها. كلما كانت مجموعة البيانات التي سيتم إختبارها أكثر تشابهًا مع البيانات الحقيقية ، كانت نتائج الاختبار أكثر موثوقية. لذلك ، غالبًا ما يكون من المنطقي قضاء الوقت وإنفاق المال في جمع مجموعة البيانات الخاصة بك ووضع علامات عليها. إذا لم يكن ذلك ممكنًا لسبب ما ، فيمكنك استخدام مجموعات البيانات العامة ، على سبيل المثال ، LFW و MegaFace. يحتوي LFW على 6000 زوج فقط من صور الوجوه وهو غير مناسب للعديد من سيناريوهات الحياة الواقعية: على وجه الخصوص ، من المستحيل قياس مستويات خطأ منخفضة بدرجة كافية في مجموعة البيانات هذه ، كما سنوضح أدناه. تحتوي مجموعة بيانات MegaFace على العديد من الصور وهي مناسبة لاختبار خوارزميات التعرف على الوجوه على نطاقات كبيرة. ومع ذلك ، فإن كلاً من مجموعة التدريب والاختبار لصور MegaFace متاحة للجمهور ، لذا يجب عليك استخدامها بحذر للاختبار.
يوجد خيار بديل هو استخدام نتائج الاختبار من قبل طرف ثالث. يتم إجراء مثل هذه الاختبارات على مجموعات كبيرة من البيانات المغلقة للأشخاص من قبل متخصصين مؤهلين ، ويمكن الوثوق بنتائجهم. أحد الأمثلة على ذلك هو إختبار NIST Face Recognition Vendor Test Ongoing. هذا اختبار أجراه المعهد الوطني للمعايير والتكنولوجيا التابع لوزارة التجارة الأمريكية (NIST). ولكن عيب هذا النهج هو أن مجموعة البيانات الخاصة بمؤسسة الاختبار قد تختلف بشكل كبير عن سيناريو الاستخدام موضع الاهتمام.
إعادة التعلم
كما قلنا، يقع التعلم الآلي في موضع القلب في البرامج الحديثة للتعرف على الوجوه. واحدة من أكثر ظواهر التعلم الآلي شيوعًا هي ما يسمى بإعادة التعلم. يتجلى ذلك في حقيقة أن الخوارزمية تظهر نتائج جيدة على الوجوه التي تم استخدامها في التعلم ، ولكن نتائج التعرف على البيانات الجديدة أسوأ بكثير.
دعونا ننظر إلي مثال محدد: تخيل عميلاً يريد تثبيت أفضل نظام للتعرف على الوجوه. لهذه الأغراض ، يقوم بتجميع مجموعة من الصور للأشخاص الذين سيسمح لهم بالوصول ، ويتعلم خوارزمية لتمييز وجوههم عن وجوه الأشخاص الآخرين. يُظهر النظام نتائج التعرف الجيدة أثناء الاختبارات ويتم تشغيل هذا النظام. بعد فترة ، قرروا توسيع قائمة الأشخاص المصرح لهم بالوصول ، وكيف يعمل نظام التعرف على الوجوه؟ يرفض النظام تصريح الوصول إلى أشخاص جدد. تم اختبار الخوارزمية على نفس الوجوه التي تم تدريبها عليها، ولم يقم أحد بقياس الدقة في الصور الجديدة. هذا، بالطبع، مثال مبالغ فيه، لكنه يساعد في فهم المشكلة.
في بعض الحالات ، يكون إعادة التدريب أو التعلم أقل وضوحًا. لنفترض أن خوارزمية التعرف على الوجوه قد تم تدريبها على صور الأشخاص حيث كان أكثر الأشخاص من مجموعة عرقية معينة. إذا استخدمت الشركة خوارزمية تحليل الوجه لمجموعات عرقية متعددة ، فمن المرجح أن تنخفض دقتها. التقدير المفرط في التفاؤل في دقة الخوارزمية بسبب الاختبار غير المناسب هو خطأ شائع جدًا. يجب عليك دائمًا اختبار الخوارزمية على البيانات الجديدة التي ستعالجها في الحقيقة ، وليس على البيانات التي تم التعلم عليها.
تلخيصًا لما سبق ، نضع قائمة بالتوصيات: لا تستخدم صورًا للوجوه التي تم تدريب الخوارزمية عليها أثناء الاختبار ، استخدم مجموعة بيانات مغلقة خاصة للاختبار. إذا لم يكن ذلك ممكنًا وستستخدم مجموعة بيانات عامة مفتوحة ، فتأكد من أن مقدم الخدمة لم يستخدمها في عملية التدريب و / أو ضبط الخوارزمية. ادرس مجموعة البيانات قبل الاختبار ، وفكر في مدى قربها من البيانات التي ستكون موجودة أثناء تشغيل النظام.
المقاييس
بعد اختيار مجموعة البيانات ، يجب أن تقرر المقياس الذي سيتم استخدامه لتقييم النتائج. في الحالة العامة ، المقياس هو وظيفة تقبل في المدخلات نتائج عمل الخوارزمية (تحديد الهوية أو التحقق) كمدخلات ، وترجع رقمًا في المخرجات يتوافق مع جودة عمل الخوارزمية على مجموعة بيانات محددة. يسمح استخدام رقم واحد للمقارنة الكمية بين الخوارزميات المختلفة أو مقدمي الخدمة المختلفين بتقديم عرض موجز لنتائج التعرف ويسهل اتخاذ القرار. في هذا القسم ، سنلقي نظرة على المقاييس الأكثر شيوعًا في التعرف على الوجوه ومناقشة آثارها من منظور الأعمال.
التحقق
يمكن النظر إلى التحقق من الوجوه على أنه عملية اتخاذ قرار ثنائي: “نعم” (صورتان تنتمي إلى نفس الشخص) ، “لا” (صورتان تظهران أشخاصًا مختلفين). قبل التعامل مع مقاييس التحقق ، من المفيد أن نفهم كيف يمكننا تصنيف الأخطاء في مثل هذه المهام. بالنظر إلى أن هناك إجابتين محتملتين للخوارزمية وخيارين للحالة الحقيقية ، فهناك 4 نتائج محتملة:

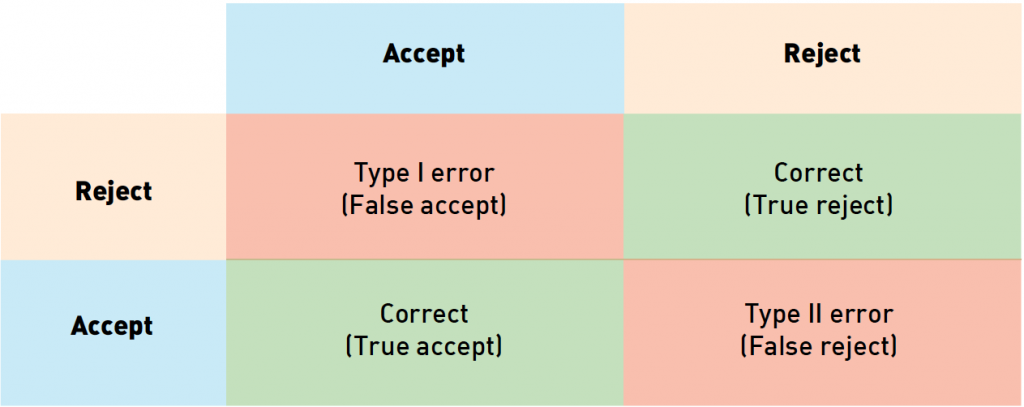
في الجدول أعلاه ، تتوافق الأعمدة مع قرار الخوارزمية (أزرق يعني قبول ، أصفر يعني رفض) ، تتوافق الصفوف مع القيم الحقيقية (مشفرة بنفس الألوان). تم تمييز الإجابات الصحيحة للخوارزمية بخلفية خضراء والخاطئة بخلفية باللون الأحمر. من بين هذه النتائج ، تتوافق اثنتان مع الإجابات الصحيحة للخوارزمية ، وتتوافق اثنتان مع أخطاء من النوع الأول والثاني. تسمى الأخطاء من النوع الأول “القبول الكاذب” أو “الإيجابية الكاذبة” أو “المطابقة الكاذبة” (تم قبولها بشكل غير صحيح) ، وتسمى الأخطاء من النوع الثاني “الرفض الكاذب” أو “السلبية الكاذبة” أو “عدم المطابقة الكاذبة” (تم رفضه بشكل غير صحيح) بجمع عدد الأخطاء من كل نوع بين أزواج الصور في مجموعة البيانات وقسمتها على عدد الأزواج ، نحصل على معدل القبول كاذب (FAR) ومعدل الرفض كاذب (FRR). في حالة نظام التحكم في الوصول ، تقابل “الإيجابية الكاذبة” منح حق الوصول إلى شخص لم يتم توفير هذا الوصول له ، بينما تعني عبارة “سلبية كاذبة” أن النظام قد رفض عن طريق الخطأ الوصول إلى شخص مخول له. هذه الأخطاء لها تكاليف مختلفة من وجهة نظر العمل ، وبالتالي يتم النظر فيها بشكل منفصل. في مثال التحكم في الوصول ، يتسبب “خطأ كاذب” في قيام ضابط الأمن بإعادة فحص تصريح الموظف. يمكن أن يؤدي إعطاء وصول غير مصرح به إلى مخالف محتمل (إيجابي كاذب) إلى عواقب أسوأ بكثير ، نظرًا لأن أنواع الأخطاء المختلفة مرتبطة بمخاطر مختلفة ، غالبًا ما تسمح الشركات المصنعة لبرامج التعرف على الوجه بضبط الخوارزمية لتقليل نوع واحد من الأخطاء. للقيام بذلك ، لا تُرجع الخوارزمية قيمة ثنائية ، بل رقمًا حقيقيًا يعكس ثقة الخوارزمية في قرارها. في هذه الحالة ، يمكن للمستخدم اختيار الحد بشكل مستقل وإصلاح مستوى الخطأ عند قيم معينة. كمثال ، نقوم بنظر مجموعة بيانات “لعبة” من ثلاث صور. لنقل أن الصورتين 1 و 2 تنتمي إلى نفس الشخص ، والصورة 3 تنتمي إلى شخص آخر. لنفترض أن البرنامج صنف ثقته لكل من الأزواج الثلاثة على النحو التالي:
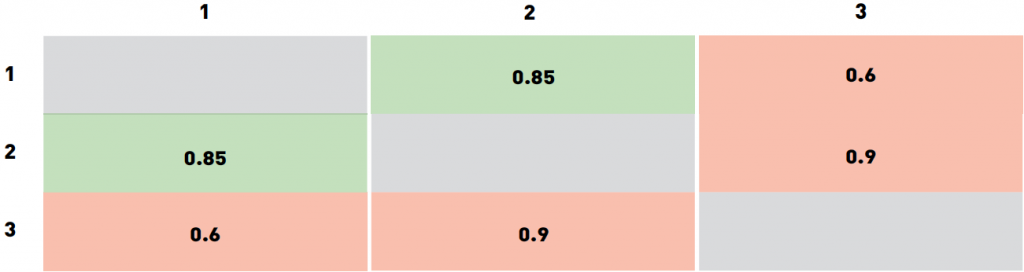
الجدول 2. مثال على قيم المصداقية لثلاث صور
لقد اخترنا القيم عن عمد حتى لا يصنف أي حد الأزواج الثلاثة بشكل صحيح. على وجه الخصوص ، أي حد أدنى من 0.6 سيؤدي إلى قبولين زائفين (للوجهين 2−3 و1−3). بالطبع، يمكن تحسين هذه النتيجة.
إختيار حد من نطاق 0.6 إلى 0.85 سينتج عنه رفض الوجهين 1−3 ، والوجهين 1−2 يتم قبولهما ، بينما الوجهين 2−3 سيتم قبولهما بشكل خاطئ. إذا قمت بزيادة الحد الأدنى إلى 0.85−0.9 ، فسيتم رفض الوجهين 1−2 بشكل خاطئ. ستؤدي قيم الحد الأعلى فوق 0.9 إلى رفضين حقيقيين (أزواج الوجوه 1−3 و2−3) ورفض واحد زائف (1−2). وبالتالي ، فإن أفضل الخيارات تبدو مثل الحد من النطاق 0.6−0.85 (قبول واحد زائف 2−3) والحد أعلى من 0.9 (تؤدي إلى الرفض الزائف 1−2). تعتمد القيمة التي يجب اختيارها على أنها نهائية على تكلفة أنواع مختلفة من الأخطاء. في هذا المثال ، يختلف الحد في نطاقات واسعة ، وهذا يرجع في المقام الأول إلى مجموعة البيانات الصغيرة جدًا وكيفية اختيارنا لقيم ثقة الخوارزمية. بالنسبة لمجموعات البيانات الكبيرة المستخدمة في مهام الحياة الواقعية ، سيتم الحصول على قيم حد أكثر دقة بشكل ملحوظ. في كثير من الأحيان ، يوفر مزودو برامج التعرف على الوجوه قيمًا افتراضية لقيم FAR مختلفة ، والتي يتم حسابها بطريقة مماثلة في مجموعات البيانات الخاصة بمزود البرامج.
من السهل أيضًا ملاحظة أنه مع انخفاض معدل المهتمين في FAR ، يلزم المزيد والمزيد من أزواج الصور الإيجابية لحساب قيمة الحد بدقة. لذلك ، بالنسبة لـ FAR = 0.001 ، هناك حاجة إلى 1000 زوج على الأقل ، وبالنسبة لـ FAR=10-66-FAR = ، يلزم وجود مليون زوج. ليس من السهل تجميع مثل مجموعة البيانات هذه وترميزها ، لذلك من المنطقي للعملاء المهتمين بقيم FAR المنخفضة الانتباه إلى المعايير العامة ، مثل اختبار NIST NIST Face Recognition Vendor Test أو MegaFace. يجب التعامل مع هذا الأخير بحذر ، نظرًا لأن عينات التدريب والاختبار متاحة للجميع ، مما قد يؤدي إلى تقييم مفرط في التفاؤل للدقة (راجع قسم “إعادة التعلم”).
منحنيات ROC
تختلف أنواع الأخطاء في التكلفة المرتبطة بها ، ولدى العميل طريقة لتحويل التوازن نحو أخطاء معينة. لهذا من الضروري النظر في مجموعة واسعة من قيم الحد. من الطرق الملائمة لتصور دقة الخوارزمية عند قيم FAR مختلفة بناء منحنيات ROC (باللغة الإنجليزية receiver operating characteristic ، خصائص المستقبل التشغيلية).
دعونا نرى كيف يتم بناء وتحليل منحنيات ROC. تأخذ ثقة الخوارزمية (ومن ثم الحد) قيمًا من فاصل زمني ثابت. بمعنى آخر ، هذه المقادير مقيدة أعلى وأسفل. لنفترض أن هذا النطاق يتراوح من 0 إلى 1. الآن يمكننا قياس عدد الأخطاء عن طريق تغيير قيمة الحد من 0 إلى 1 بزيادات صغيرة. لكل قيمة حدية ، نحصل على قيم FAR و TAR (معدل القبول الحقيقي). بعد ذلك ، سنرسم كل نقطة بحيث يتوافق FAR مع محور الحد الأقصي، و TAR يتوافق مع المحور التنسيقي الإحداثي.
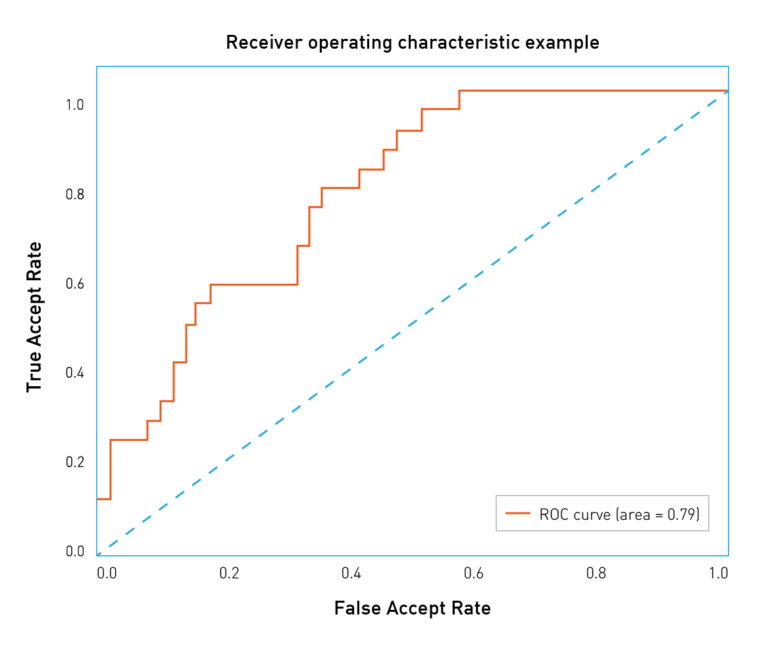
من السهل ملاحظة أن إحداثيات النقطة الأولى ستكون 1،1. مع حد بقيمة 0 ، نقبل جميع أزواج الوجوه ولا نرفض أيًا منها. وبالمثل ، ستكون النقطة الأخيرة 0،0: عند حد 1 ، لا نقبل أي زوج من الوجوه ونرفض جميع أزواج الوجوه. في النقاط أخرى ، يكون المنحنى محدبًا عادةً. يمكنك أيضًا ملاحظة أن المنحنى الأسوأ يقع تقريبًا على القطر المائل للرسم البياني ويتوافق مع التخمين عشوائي للنتيجة. من ناحية أخرى ، فإن أفضل منحنى يكون مثلثًا برؤوسه (0،0) (0،1) و (1،1). ولكن في مجموعات البيانات ذات الحجم المعقول ، يصعب مقابلة مثل هذه المنحنيات.
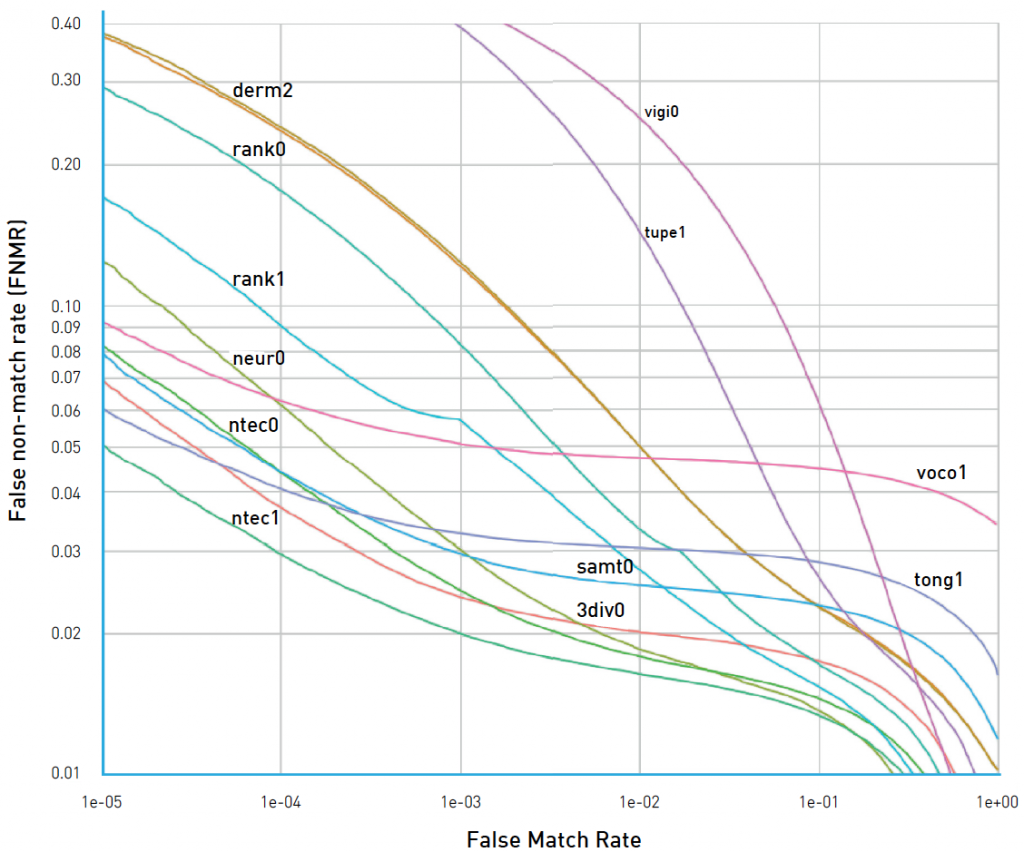
يمكن رسم مثل منحنيات ROC باستخدام مقاييس / أخطاء مختلفة علي المحاور. قم بالنظر ، على سبيل المثال ، إلي الشكل 4. فيه واضح أن منظمي NIST FRVT قد رسموا FRR على المحور Y (معدل عدم تطابق زائف في الشكل) ،و FAR على المحور X (معدل تطابق زائف في الشكل). في هذه الحالة بالذات ، يتم تحقيق أفضل النتائج من خلال المنحنيات الموجودة بالأسفل والمزاحة إلى اليسار ، وهو ما يتوافق مع معدلات FRR و FAR المنخفضة. لذلك ، يجدر الانتباه إلى القيم المرسومة على طول المحاور.
مثل هذا الرسم البياني يجعل من السهل الحكم على دقة الخوارزمية بالنسبة إلى FAR معين: يكفي العثور على نقطة على المنحنى مع إحداثي X يساوي FAR المطلوب وقيمة TAR المقابلة. يمكن أيضًا تقدير “جودة” منحنى ROC برقم واحد ، لذلك تحتاج إلى حساب المنطقة تحته. في هذه الحالة ، ستكون أفضل قيمة ممكنة هي 1 ، والقيمة 0.5 تقابل تخمينًا عشوائيًا. هذا الرقم يسمى ROC AUC (المنطقة تحت المنحنى). ومع ذلك ، تجدر الإشارة إلى أن ROC AUC تفترض ضمنيًا أن أخطاء النوع الأول والنوع الثاني مؤكدين ، ولكن ليس هذا هو الحال دائمًا. إذا اختلفت تكلفة الأخطاء ، يجب الانتباه إلى شكل المنحنى والمناطق التي يلبي فيها FAR متطلبات العمل.
تحديد الهوية
المهمة الثانية الشائعة للتعرف على الوجوه هي تحديد الهوية أو العثور على الوجه المطلوب بين مجموعة من الصور. يتم فرز نتائج البحث عن الوجوه حسب ثقة الخوارزمية ، وتكون المطابقات الأكثر احتمالاً في أعلى القائمة. اعتمادًا على ما إذا كان الشخص الذي تم البحث عنه موجودًا في قاعدة بيانات البحث عن الأشخاص أم لا ، يتم تقسيم تحديد الهوية إلى فئتين فرعيتين: تحديد هوية في مجموعة مغلقة (معروف أن الشخص الذي يتم البحث عنه موجود في قاعدة البيانات) وتحديد هوية في مجموعة مفتوحة (الشخص الذي يتم البحث فيه قد لا يكون في قاعدة بيانات الوجوه).
الدقة (accuracy) هي مقياس موثوق ومفهوم لتحديد الهوية في مجموعة مغلقة. في الواقع تقيس الدقة بشكل أساسي عدد المرات التي كان فيها الشخص المطلوب ضمن نتائج البحث عن الوجوه.
كيف تعمل في الواقع؟ دعونا نفهم ذلك. لنبدأ بصياغة متطلبات العمل. لنفترض أن لدينا صفحة ويب يمكنها وضع عشر نتائج للبحث. نحتاج إلى قياس عدد المرات التي يقع فيها الشخص الذي تبحث عنه في أول عشرة إجابات من الخوارزمية. يسمى هذا الرقم بالدقة Top-N(في هذه الحالة بالذات ، N تساوي 10).
لكل إختبار ، نحدد صورة الشخص الذي سنبحث عنه ومعرضًا للوجوه التي سنبحث فيها ، بحيث يحتوي المعرض على صورة أخرى على الأقل لهذا الشخص. نحن ننظر إلى النتائج العشر الأولى لعمل خوارزمية البحث ونتحقق مما إذا كان الشخص الذي نبحث عنه من بينها. للحصول على الدقة ، قم بجمع جميع التجارب التي كان فيها الشخص الذي تم البحث عنه في نتائج البحث وقسمه على إجمالي عدد التجارب.

يتألف تحديد الهوية في المجموعة المفتوحة من العثور على الأشخاص الأكثر تشابهًا مع الصورة المطلوب البحث عنها وتحديد ما إذا كان أي منهم هو الشخص المطلوب بناءً على ثقة الخوارزمية. يمكن اعتبار تحديد الهوية في المجموعة المفتوحة مزيجًا من تحديد الهوية في مجموعة مغلقة والتحقق ، وبالتالي ، يمكن تطبيق جميع المقاييس نفسها على هذه المهمة كما في مهمة التحقق. من السهل أيضًا رؤية أنه يمكن اختزال تحديد الهوية في المجموعة المفتوحة إلى مقارنات زوجية للصورة المرغوبة مع جميع الصور من معرض الصور. في الممارسة العملية ، لا يتم استخدام هذا لأسباب تتعلق بالسرعة الحسابية. غالبًا ما يأتي برنامج التعرف على الوجوه مزودًا بخوارزميات بحث سريعة يمكنها العثور على وجوه متشابهة بين ملايين الوجوه في أجزاء من الثانية. بينما تستغرق المقارنات بين أزواج الصور وقتًا أطول.
أمثلة عملية
علي سبيل التوضيح ، دعونا نلقي نظرة على بعض الأمثلة التي توضح كيفية قياس جودة خوارزميات التعرف على الوجوه للمقارنة في سيناريو حقيقي.
متجر البيع بالتجزئه
لنفترض أن متجر تجزئة متوسط الحجم يريد تحسين برنامج ولاء العملاء أو تقليل عدد السرقات. من حيث القياسات الحيوية للوجه ، فهما نفس الشيء تقريبًا. الهدف الرئيسي من هذا المشروع هو التعرف على زبون منتظم أو شخص محتال من صورة الكاميرا في أقرب وقت ممكن وتمرير هذه المعلومات إلى البائع أو مسؤول الأمن.
دع برنامج ولاء العملاء يغطي 100 عميل. يمكن اعتبار هذه المهمة كمثال على تحديد الهوية في مجموعة مفتوحة. بعد تقييم التكاليف ، خلص قسم التسويق إلى أن المستوى المقبول للخطأ هو الخلط بين زائر وزبون متكرر في اليوم. إذا تمت زيارة المتجر من قبل 1000 زائر يوميًا ، و كل منهم يجب التحقق منه مقابل قائمة تضم 100 عميل منتظم ، فسيكون 1 / (1000 * 100) =10-5.
بعد تحديد مستوى الخطأ المقبول ، يجب عليك اختيار مجموعة البيانات المناسبة للاختبار. قد يكون الخيار الجيد هو وضع الكاميرا في مكان مناسب (يمكن لمزودي الخدمة المساعدة بجهاز وموقع معين). من خلال مطابقة معاملات العملاء حاملي بطاقة الولاء مع صور الكاميرا وإجراء التصفية اليدوية ، يمكن لموظفي المتجر جمع مجموعة من الأزواج “الإيجابية”. من المنطقي أيضًا جمع مجموعة من الصور للزوار العشوائيين (صورة واحدة لكل شخص). يجب أن يتوافق العدد الإجمالي للصور تقريبًا مع عدد زوار المتجر يوميًا. من خلال الجمع بين المجموعتين ، يمكنك الحصول على مجموعة بيانات من أزواج “إيجابية” و “سلبية”.
يجب أن يكفي حوالي ألف من الأزواج “الإيجابية” للتحقق من دقة التعرف المطلوبة. من خلال الجمع بين العديد من العملاء المنتظمين والزوار العاديين ، يمكن جمع حوالي 100000 زوج “سلبي”.
الخطوة التالية هي تشغيل (أو مطالبة مقدم الخدمة بتشغيل) البرنامج والحصول على ثقة الخوارزمية لكل زوج من مجموعة البيانات. بمجرد الانتهاء من عمل ذلك ، يمكن رسم منحنى ROC والتحقق من أن عدد العملاء الدائمين المحددين بشكل صحيح في FAR=10-5 يلبي متطلبات العمل.
البوابة الإلكترونية بالمطار
تخدم المطارات الحديثة عشرات الملايين من الركاب سنويًا ، ويمر حوالي 300000 شخص من منطقة مراقبة ضباط الهجرة والجوازات في السفر والوصول كل يوم. سيؤدي إتمام هذه العملية بشكل إلكتروني إلى تقليل التكاليف بشكل كبير. من ناحية أخرى ، من غير المرغوب فيه للغاية السماح للمخالفين بالمرور ، وتريد إدارة المطار تقليل مخاطر مثل هذا الحدث. FAR=10-7 يطابق عشرة مخالفين في السنة ويبدو معقولاً في هذه الحالة. إذا كانت قيمة FRR بالنسبة إلى FAR هي 0.1 (وهو ما يتوافق مع نتائج NtechLab في معيار NIST visa images) فيمكن تقليل تكلفة التحقق اليدوي من المستندات بمقدار عشرة أضعاف. ومع ذلك ، لتقدير الدقة عند مستوى FAR معين ، هناك حاجة لعشرات الملايين من الصور. يتطلب جمع مثل هذه المجموعة الكبيرة من البيانات أموالًا كبيرة وقد يتطلب موافقة إضافية على معالجة البيانات الشخصية. نتيجة لذلك ، يمكن أن تستغرق الاستثمارات في مثل هذا النظام وقتًا طويلاً لتؤتي ثمارها. في هذه الحالة ، من المنطقي الرجوع إلى تقرير اختبار NIST Face Recognition Vendor Test، والذي يحتوي على مجموعة بيانات تحتوي على صور للأشخاص الحاصلين على تأشيرات. يجب أن تختار إدارة المطار مزود الخدمة بناءً على الاختبار القائم على مجموعة البيانات هذه ، مع مراعاة حركة الركاب.
المراسلات البريدية الموجهة المستهدفة
حتى الآن ، نظرنا في الأمثلة التي كان العميل مهتمًا فيها بمعدل FAR المنخفض ، ولكن هذا ليس هو الحال دائمًا. لنتخيل حامل إعلاني مجهز بكاميرا في مركز تسوق كبير. مركز التسوق لديه برنامج ولاء خاص به ويرغب في تحديد هوية المشاركين فيه الذين توقفوا عند الحامل الإعلاني. لاحقا ، يمكن إرسال رسائل موجهة إلى هؤلاء الأشخاص مع خصومات وعروض شيقة بناءً على ما يثير اهتمامهم في الحامل الإعلاني.
لنفترض أن تكلفة تشغيل مثل هذا النظام تبلغ 10 دولارات ، بينما يتوقف حوالي 1000 زائر يوميًا عند الحامل الإعلاني. قدر قسم التسويق الربح من كل بريد إلكتروني مستهدف بـ 0.0105 دولار. نود تحديد هوية أكبر عدد ممكن من العملاء الدائمين وعدم إزعاج البقية كثيرًا. لكي تؤتي هذه المراسلات ثمارها ، يجب أن تكون الدقة مساوية لتكلفة الحامل الإعلاني مقسومة على عدد الزوار والدخل المتوقع من كل رسالة. على سبيل المثال ، الدقة تساوي 10 / (1000 * 0.0105) = 95٪. يمكن لإدارة المركز التجاري جمع مجموعة البيانات بالطريقة الموضحة في قسم “متجر البيع بالتجزئة” وقياس الدقة كما هو موضح في قسم “تحديد الهوية”. بناءً على نتائج الاختبار ، يمكن اتخاذ قرار فيما إذا كان من الممكن الحصول على الفائدة المتوقعة باستخدام نظام التعرف على الوجوه.
التطبيق العملي
دعم الفيديو
في هذه المنشور ، ناقشنا بشكل أساسي العمل مع الصور ولم نتطرق إلى تدفق الفيديو. يمكن اعتبار الفيديو على أنه تسلسل للصور الثابتة ، لذا فإن المقاييس والأساليب الخاصة باختبار الدقة على الصور قابلة للتطبيق على الفيديو أيضًا. وتجدر الإشارة إلى أن معالجة تدفق الفيديو أغلى بكثير من حيث الحسابات التي يتم إجراؤها وتفرض قيودًا إضافية على جميع مراحل التعرف على الوجوه. يجب إجراء اختبار الأداء بشكل منفصل عند العمل مع الفيديو ، لذلك لا يتم تناول تفاصيل هذه العملية في هذا النص.
أخطاء شائعة
في هذا القسم ، نرغب في سرد المشاكل والأخطاء الشائعة التي تحدث عند اختبار برنامج التعرف على الوجوه وتقديم توصيات حول كيفية تجنبها.
الإختبار على مجموعة بيانات ذات حجم غير كافي
يجب أن تكون دائمًا حذرًا عند اختيار مجموعة البيانات لاختبار خوارزميات التعرف على الوجوه. يجب أن تكون دائمًا حذرًا عند اختيار مجموعة البيانات لاختبار خوارزميات التعرف على الوجوه. يجب إختيار حجم مجموعة البيانات بناءً على متطلبات العمل وقيم FAR / TAR. ستتيح لك مجموعات البيانات “التجريبية” المكونة من عدة صور لوجوه الأشخاص من مكتبك “تجربة” الخوارزمية أو قياس أدائها أو اختبار المواقف غير القياسية ، ولكن لا يمكنك استخلاص استنتاجات حول دقة الخوارزمية بناءً عليها. يجب استخدام مجموعات البيانات ذات الحجم المعقول لاختبار الدقة.
الإختبار عند قيمة حدية وحيدة
في بعض الأحيان ، يختبر الأشخاص خوارزمية نظام التعرف على الوجوه عند حد ثابت واحد (غالبًا ما يكون تم إختياره “افتراضيًا” من قبل الشركة المصنعة) ويأخذون في الاعتبار نوعًا واحدًا فقط من الخطأ. هذا غير صحيح لأن الحدود “الافتراضية” تختلف من مقدم خدمة لآخر ، أو يتم اختيارها بناءً على قيم FAR أو TAR مختلفة. عند الاختبار ، يجب الانتباه إلى كلا النوعين من الأخطاء.
مقارنة النتائج على مجموعات البيانات المختلفة
تختلف مجموعات البيانات من حيث الحجم والجودة والتعقيد ، لذا لا يمكن مقارنة نتائج عمل الخوارزميات على مجموعات بيانات مختلفة. يمكنك بسهولة رفض الحل الأفضل لمجرد أنه تم اختباره على مجموعة بيانات أكثر تعقيدًا من التي عند المنافس.
قم بالاستنتاجات بناءً على اختبار على مجموعة بيانات وحيدة
يجب أن تحاول الاختبار على مجموعات بيانات متعددة. عند اختيار مجموعة بيانات عامة وحيدة ، لا يمكنك التأكد من عدم استخدامها عند تعليم الخوارزمية أو ضبطها. في هذه الحالة ، سيتم المبالغة في الدقة. لحسن الحظ ، يمكن تقليل احتمالية حدوث هذا الحدث من خلال مقارنة النتائج علي مجموعات البيانات المختلفة.
النتائج
في هذا المنشور ، وصفنا الأجزاء الأساسية لاختبار خوارزميات التعرف على الوجوه: مجموعات البيانات والمهام والمقاييس ذات الصلة والسيناريوهات الشائعة.
بالطبع ، هذا ليس كل ما نود إخبارك به عن الاختبار ، وقد يختلف أفضل مسار للعمل في ظل العديد من السيناريوهات الاستثنائية (سيسعد فريق NtechLab بمساعدتك في إيجاد حل لذلك). لكننا نأمل حقًا أن يساعدك هذا النص في التخطيط للاختبار بشكل صحيح ، ومقارنة العديد من خوارزميات التعرف على الوجوه ، وتقييم جوانب القوة والضعف فيها ، وتفسير مقاييس الجودة من حيث مهام العمل المطلوبة ، من أجل اختيار أفضل نظام للتعرف على الوجوه في النهاية.
أصدقاء! كالعادة ، نتطلع إلى تعليقاتكم على هذا الموضوع.